
27 september 2019
En första tillämpning av maskininlärning
I förra delen i den här bloggserien började vi titta på ett exempel där vi ville kategorisera ärenden automatiskt. I den här delen fortsätter vi med exemplet och tittar på hur vi kan använda resultatet i vår verksamhet när vi tillämpar maskininlärning.
Kategorisering av ärenden
Kategorisering är ett brett begrepp som kan betyda olika saker beroende på sammanhanget. I vårt fall kommer vi titta på klustring, vilket är automatisk kategorisering där kategorierna inte är givna från början. Ett annat alternativ är klassificering, där kategorierna (eller klasserna) är kända och givna från början.
I vårt exempel med klustring av ärenden kommer vi arbeta med exempelärenden där vi känner till ärendenas kategori. Vi kan använda denna kunskap för att utvärdera hur väl vår klustringsmetod presterar. För att tillämpa vårt resultat kan vi sedan jämföra nya ärenden med varje kluster och tilldela ärendet till den kategori vars kluster är ”mest likt” vårt nya ärende.
Figuren nedan visar hur en indelning i två kluster kan se ut. I det här exemplet tillhör varje punkt ett kluster, men det är tänkbart att ignorera punkter som ligger långt från varje klusters mittpunkt.
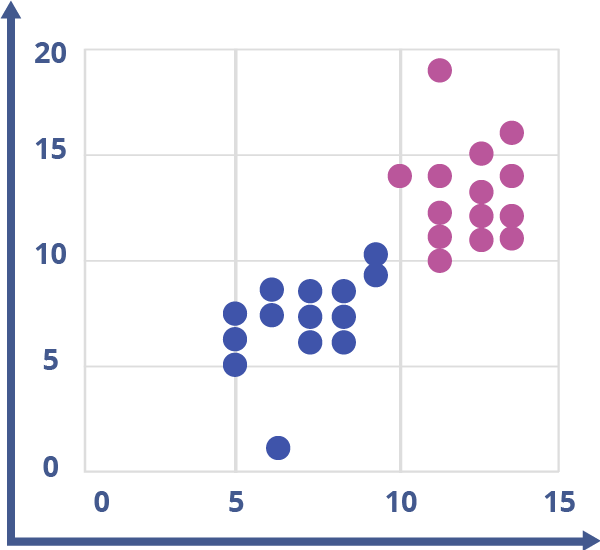
Krav på vår data
Innan vi sätter igång med klustring av våra ärenden behöver vi titta på hur träningsdatat ser ut och hur vi behöver preparera det innan vi använder det. Träningsdatat i det här exemplet består av 150 ärenden som är indelade i de tre kategorierna IT, HR och Övrigt. Så här ser ett av exempelärendena ut:
Rubrik: ”Kan inte skriva ut på plan 4”
Ärendebeskrivning: ”När jag försöker skriva ut mina dokument på plan 4 så får jag ett felmeddelande att skrivaren inte finns i domänen.
Jag har även försökt med skrivarna på plan 5 och plan 6, och där funkar det bra. Jag tror att några kollegor hade samma problem förra veckan.”
Skapat av: Erik Öberg
Bifogade filer: ”My_screenshot.png”
Ärendekategori: IT
Innan vi sätter igång med klustring gör vi om parametrarna till numeriska värden på detta sätt:
| Ursprunglig parameter | Ny numerisk parameter |
| Rubrik | Antal ord i rubriken |
| Ärendebeskrivning | Antal ord i texten |
| Bifogade filer | Antal bifogade filer |
Som första ansats hoppas vi att det räcker med tre numeriska parametrar. Kom ihåg att ärendekategorin är känd för alla exempelärenden, vilket ger oss möjlighet att använda den parametern som ”facit” för att utvärdera hur väl vår metod fungerar i efterhand. Vårt exempelärende ovan kan nu beskrivas så här:
Antal ord i rubriken: 7
Antal ord i texten: 48
Antal bifogade filer: 1
Automatisering
Nu är vi redo att köra igång med klustringen. Det gör vi genom att använda en enkel algoritm som endast kräver att vi anger antal kluster. Vi behöver inte förklara för algoritmen vad vårt data betyder eller vilka ärenden som liknar varandra, utan det kommer vi låta algoritmen tala om för oss.
Det finns en mängd olika klustringsalgoritmer och i det här exemplet ska vi använda en av de enklaste klustringsalgoritmerna som kräver att vi i förväg specificerar hur många kluster datat ska delas in i. Som resultat kommer vi få tillbaka alla exempelärenden med en siffra som talar om vilket kluster ärendet tillhör. Eftersom vi i förväg vet att ärendena tillhör någon av kategorierna IT, HR och Övrigt kommer vi be vår algoritm att returnera alla ärenden med en siffra mellan 1 och 3. Det finns mer avancerade klustringsalgoritmer som kan lista ut rimligt antal kluster själv, men här börjar vi på enklast möjliga vis.
Vår valda algoritm börjar med att slumpmässigt placera ut tre kluster som täcker alla exempelärenden. Därefter räknar algoritmen steg för steg fram hur ärendena ska omplaceras för att till slut få alla ”liknande” ärenden i samma kluster. Som mått på ”liknande” används det euklidiska avståndet mellan ärendena. Algoritmen känner själv av när den är färdig genom att mittpunkterna i klustren inte längre rör sig från ett steg till nästa. Vi säger att algoritmen har konvergerat till en lösning. (Vi kan dock inte vara säkra på att lösningen är optimal på grund av att startläget är valt slumpmässigt. Det är dessutom inte självklart vad en ”optimal lösning” betyder, men det spar vi till en annan gång...)
Resultat och slutsats
Hur väl stämmer resultatet med ”facit”? Tabellen nedan visar hur stor andel av ärendena i vårt exempel som har placerats i respektive kluster. Det verkar som att samtliga IT-ärenden har samlats i ett och samma kluster. Ärendena i de andra två kategorierna har i stort sett separerats, men med viss överlappning åt bägge håll. Totalt har 135 av 150 ärenden placerats i kluster som stämmer väl med våra ursprungliga kategorier. Det betyder att 90% av ärendena har hamnat rätt.
| Kluster | IT | HR | Övrigt |
| 1 | 100% | ||
| 2 | 96% | 4% | |
| 3 | 26% | 74% |
Resultatet är typiskt för den här typen av tillämpning. Vissa delar av den underliggande ”sanningen” överlappar, vilket gör att vi inte får fullständig separation av våra träningsexempel. Det kan man enkelt förstå genom att se att det finns ärenden som har samma parametrar, men som tillhör olika kategorier (det finns både ett HR-ärende och ett Övrigt-ärende som har 12 ord i rubriken och 2 bifogade filer.)
Tolkningen av detta är att det inte räcker med de tre numeriska parametrarna i vår ansats för att fullständigt separera kategorierna. Faktum är att det inte nödvändigtvis går att separera de förekommande kategorierna i den här typen av problem. Men vi kan vinna mycket i en praktisk tillämpning av en bra lösning, även om den inte är optimal.
Operationalisera
Nu kan vi använda vår inlärda modell för att göra förutsägelser om framtida ärenden. Det går till så att vi jämför nya ärenden med mittpunkterna för varje kluster och automatiskt tilldelar det nya ärendet till den kategori vars klustermittpunkt ligger närmast det nya ärendet. Ett enklare sätta uttrycka detta på är att vi automatiskt stoppar varje nytt ärende i den “hink” där liknande ärenden redan finns.
I nästa del av den här bloggserien ska vi titta på hur vi kan få större tillförlitlighet i vårt resultat genom att analysera och välja ut parametrar så att överlappning mellan kategorier (kluster) minskar.
Läs även de två första delarna av bloggserien:
Del 1: Kom igång med maskininlärning
Del 2: Så kan du tillämpa maskininlärning i din verksamhet
Vi på Multisoft hjälper dig gärna med att komma igång vare sig det gäller ett specifikt fall, eller rent allmänt för att göra en genomlysning av verksamhetens data inom olika områden inom just din verksamhet. Läs mer om hur vi jobbar med AI.


