
5 november 2019
Beslutsträd – kategorisera ditt data och förstå varför
Det finns många metoder för att automatiskt kategorisera data. Metoderna kan delas in i två grupper, de metoder där underliggande mekanismer är dolda, och de metoder där vi förutom själva kategoriseringen även får ett svar på vad kategoriseringen innebär. I den här artikeln ska vi titta på beslutsträd och hur de kan användas för att kategorisera data på ett sätt som gör det möjligt för oss att enkelt förstå vad resultatet betyder.
Vad är ett beslutsträd?
Ett beslutsträd är en trädliknande struktur med en rotnod överst och därunder grenar som delar sig nedåt nivå efter nivå baserat på ett parametervillkor i varje klyka. Längst ned i trädet finns lövnoder som motsvarar de klasser eller värden som man har som ”facit” för sitt data.

Figur 1: Ett beslutsträd med villkor i två nivåer och med tre kategorier som "facit".
Det fina med beslutsträd som modell för vårt data är både att vi kan träna modellen med befintligt data och få en visuell förklaringsmodell till varför varje datapunkt tillhör respektive kategori, och att vi kan använda trädet för att kategorisera framtida datapunkter. Med andra ord får vi alltså en karta över både historik och framtid.
Beslutsträdets uppbyggnad
Grundtanken för ett beslutsträds uppbyggnad är att automatiskt sätta villkoren uppifrån och ned för varje förgrening på ett sådant sätt att vi får så bra uppdelning i lövnoderna som möjligt. Vi låter förgreningen fortsätta tills det stoppvillkor vi angivit är uppfyllt.
En viktig egenskap hos beslutsträdet att det generaliserar baserat på träningsdatat, vilket innebär att det inte kategoriserar datapunkterna med 100 % träffsäkerhet. Det är en medveten begränsning som vi väljer att ändå acceptera om det ger oss en enkel modell som tillåter överblick och generalisering med nära nog perfekt kategorisering.
Det centrala i uppbyggandet av beslutsträdet är att sätta vettiga villkor för när det är lämpligt att avsluta varje gren. Om man inte har något villkor alls får man i princip ett träd som är så stort att varje lövnod motsvarar en datapunkt i ursprungsdatat. Ett sådant träd vore meningslöst att ta fram eftersom det nästan blir omöjligt att överblicka. Ett sådant träd ger dessutom inte någon användbar generalisering eller insikt av hur datat är strukturerat.
Det man helst vill uppnå är ett träd med rimligt lågt antal nivåer, kanske någonstans mellan tre och tio nivåer. Då kan vi både överblicka trädet enkelt, och dra slutsatser om datastrukturen.
Beskär ditt träd
För att säkerställa att trädet blir lagom stort kan man utgå från snäva villkor och bygga upp trädet konservativt, men det går även att i efterhand beskära trädet för att kapa sådana grenar som inte tillför så mycket insikt till hur datat är uppdelat. Det går inte att avgöra vilket som är bäst i förväg, utan man får prova sig fram med olika tekniker tills man får ett träd som är rimligt stort för respektive tillämpning.
Ju mer vi beskär trädet, desto enklare träd får vi men med konsekvensen att generaliseringen blir mindre träffsäker. Var vi väljer att dra gränsen behöver vi experimentera fram från fall till fall.

Figur 2. Trädet från figur 1 har beskurits på vänster sida så att endast kategori B återstår för alla datapunkter efter den första förgreningen.
Exempel och slutsats
Låt oss titta på ett exempel med kategorisering av ärenden. Ärendena kan tillhöra en av de tre kategorierna HR, IT och Ekonomi. För att träna ett beslutsträd har vi tillgång till gamla ärenden där kategorin redan är satt, dvs. vi har ”facit” för dessa ärenden.
För att börja på enklast möjliga sätt väljer vi tre numeriska parametrar som beskriver ett ärende så här:
- Antal ord i rubriken
- Antal ord i ärendebeskrivningen
- Antal bifogade filer
Nu vill vi ta fram ett beslutsträd för att kunna få en visuell karta över hur ärendenas parametrar påverkar vilken kategori de tillhör, samt kunna använda trädet för att tilldela framtida ärenden en av de tre kategorierna.
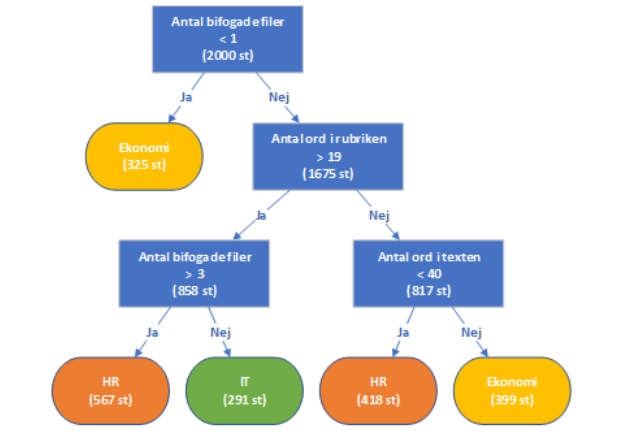
Figur 3. Det färdiga beslutsträdet baserat på våra 2000 exempelärenden. Inom parentes visas antal ärenden som återstår efter varje steg.
Som vi ser i figuren har beslutsträdalgoritmen valt parametern ”Antal bifogade filer” som rotnod. Alla ärenden som saknar bifogade filer är entydigt kategoriserade som ekonomiärenden, och det lyckades algoritmen fånga upp.
Därefter har resterande ärenden i stort sett delats i två lika stora delar baserat på parametern ”Antal ord i rubriken” med tröskelvärdet 19 ord.
Slutligen har två ytterligare uppdelningar gjorts på två olika parametrar för att skapa de sista fyra lövnoderna.
Det färdiga trädet ger oss möjlighet att enkelt överblicka vilka parametrar som ger respektive kategori. Vi kan nu också använda trädet för att kategorisera framtida ärenden. Vi kan nämligen spara trädet som inlärd modell, vilket ger oss möjlighet att kategorisera stora mängder ärenden snabbt och effektivt genom exempelvis import av ärenden i Excel-format. Eller ännu bättre, genom att löpande ta emot inkommande ärenden och tilldela en kategori automatiskt i ett system.
Läs även de fyra första delarna av bloggserien:
Del 1: Kom igång med maskininlärning
Del 2: Så kan du tillämpa maskininlärning i din verksamhet
Del 3: En första tillämpning av maskininlärning
Del 4: Hur kan vi automatiskt preparera ett dataset
Vi på Multisoft hjälper dig gärna med att komma igång vare sig det gäller ett specifikt fall, eller rent allmänt för att göra en genomlysning av verksamhetens data inom olika områden inom just din verksamhet. Läs mer om hur vi jobbar med AI.


