
3 oktober 2019
Hur kan vi automatiskt preparera ett dataset
I den här delen ska vi titta på hur vi automatiskt kan preparera ett dataset så att vi får färre parametrar att ta hänsyn till innan vi arbetar vidare med datat. Det finns flera metoder att välja på som gemensamt går under beteckningen dimensionsreduktion. Det är ett kraftfullt sätt att begränsa vårt data samtidigt som vi behåller så mycket som möjligt av variansen eller informationen i datat.
Syfte och motivering till dimensionsreduktion
Det finns två goda skäl till att reducera antalet parametrar i ett dataset:
- Vi kan enklare visualisera datat om det är färre parametrar. Särskilt gäller detta om vi reducerar till två parametrar.
- Vi kan välja hur den nya uppsättningen parametrar ska se ut för att passa det vi vill göra i nästa steg. Exempelvis kan vi välja att den nya parameteruppsättningen ska maximera informationsinnehåll eller maximera separation mellan kategorier i datat.
I den här artikeln ska vi se reducera antalet parametrar från fyra till två för att kunna visualisera datat på ett enkelt sätt och för att få maximal separation mellan klasser för vidare bearbetning i nästa steg.
Exempeldata och kriterium för val av parametrar
Exempeldata i det här fallet är Iris-datasetet, framtaget av Fisher på 1930-talet (!). Datat består av 150 datapunkter med vardera 50 punkter i tre klasser; Setosa, Virginica och Versicolor. De tre klasserna är tre arter inom blomsläktet Iris. Varje datapunkt har fyra parametrar för längd och bredd av kronblad respektive foderblad.
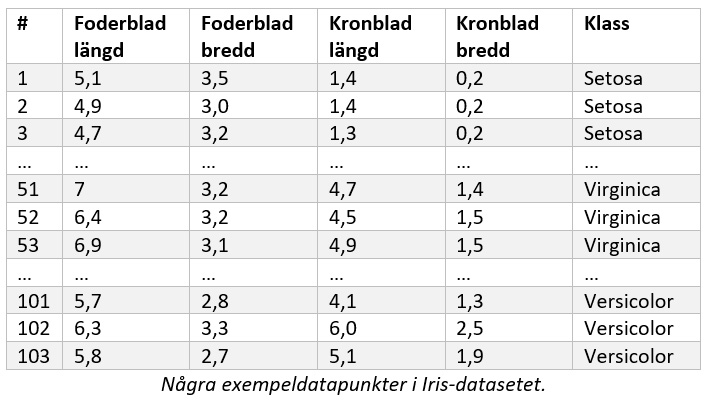
Vi behöver ange ett kriterium för att avgöra vad som ska spela roll vid reduktion av antalet parametrar. I det här exemplet väljer vi som kriterium att modellen ska välja de parametrar som maximerar separationen mellan de kända klasser vi har i vårt data. För detta syfte finns en metod som kallas linjär diskriminantanalys. Mer om metoden kommer längre ned i den här artikeln.
Hur ser datat ut?
Innan vi börjar bearbeta datat kan vi bilda oss en uppfattning om hur datat ser ut genom att plotta två parametrar i taget. Figur 1 visar att det finns en tydlig separation mellan en av klasserna och de två andra. Däremot är det otydligt hur vi på bästa sätt väljer ut de parametrar som ger bäst separation.
Uppgiften består nu i att reducera datasetets dimension från fyra parametrar till två på ett sådant sätt att separationen mellan klasserna är maximal.
Därefter kan vi gå vidare och tillämpa andra modeller, exempelvis klustring. Eftersom vi har säkerställt att de nya parametrarna ger en maximal separation kan vi räkna med mindre överlappning mellan klasserna än det var i originaldatat som bestod av fyra parametrar.

Figur 1. Alla kombinationer av de fyra parametrarna i Iris-datasetet. Blå = Setosa, Orange = Virginica, Grå = Versicolor.
Metodik
Linjär diskriminantanalys är en statistisk metod och inlärningen består i att vi lagrar de nya parametrarna som modellen tar fram för att kunna använda dem för vidare arbete och klassificering av framtida datapunkter. Den inlärda modellen är alltså ett dataset som består av 150 datapunkter med två parametrar och de ursprungliga klasserna. Hur många nya parametrar vi vill ha i det nya datasetet kan vi välja. För att kunna plotta datasetet på ett bra sätt väljer vi två parametrar i detta fall. (Ett annat alternativ hade varit att välja tre parametrar men då hade vi varit tvungna att göra en 3D-plot för att visualisera datat, vilket hade varit onödigt krångligt.)
Resultat och slutsats
Resultatet från vår valda metod är alltså ett dataset där varje datapunkt består av två parametrar istället för fyra. Hur punkterna fördelar sig efter att vi tillämpat metoden visas i figur 2. De två nya parametrarna motsvarar inte någon av de ursprungliga parametrarna, utan är sammansatta kombinationer av de dessa. Det betyder att vi inte enkelt kan översätta vad de två nya parametrarna betyder i termer av de ursprungliga parametrarna. Istället kan vi betrakta de nya parametrarna som en modell med syfte att förenkla vidare arbete.

Den första parametern ger den maximala separationen (horisontellt) och den andra parametern är ortogonal (vinkelrät) mot den första parametern. Som vi ser har vi uppnått två saker samtidigt: Maximal separation mellan klasser och tydlig visualisering av detta.
Vi kan nu gå vidare med ytterligare bearbetning, exempelvis klustring som vi tittat på tidigare i den här bloggserien.
Läs även de tre första delarna av bloggserien:
Del 1: Kom igång med maskininlärning
Del 2: Så kan du tillämpa maskininlärning i din verksamhet
Del 3: En första tillämpning av maskininlärning
Vi på Multisoft hjälper dig gärna med att komma igång vare sig det gäller ett specifikt fall, eller rent allmänt för att göra en genomlysning av verksamhetens data inom olika områden inom just din verksamhet. Läs mer om hur vi jobbar med AI.


